Hackergame Writeup 2023 : A Newbie Perspective
Hackergame Writeup : A Newbie Perspective
0. 一些废话

对如上标题的额外补充:

过去这么多年,今年是第一次正儿八经拿时间来打 Hackergame ,得益于今年接近溢出的 Misc 浓度,对我这个菜鸡来说,抢个一血的正反馈确实不错,被排行榜卷得写不下项目查资料的过程也确实折磨。

最先和 Hackergame 交集应该是 2019 年,当观众。
然后是去年(2022),卷不动题去做了个文化衫,中了,现在还在穿,暂时不知道今年还收不收 看样子没了。

扯远了,对今年的 Hackergame 我的评价是:入门题更友好了,高端题更卷了,排行榜争抢更激烈了。不过确实得强调,自己的菜是原罪嘛。
因为爆出来的都是简单题(且很多包含运气成分),所以有些不好截图的地方也不详细写了,出题人肯定写得比我详细,Writeup 大体上以做题顺序排列。
1. Hackergame 启动
按照 Hackergame 签到题的一贯尿性,进网页直接 F12 看请求。点提交按钮后注意到 https://cnhktrz3k5nc.hack-challenge.lug.ustc.edu.cn:13202/?similarity=
尝试改为 similarity=1 后:

盲猜没校验,直接 similarity=1000 ,完成


2. 更深更暗
F12, 启动!
Ctrl + F 搜索,启动!
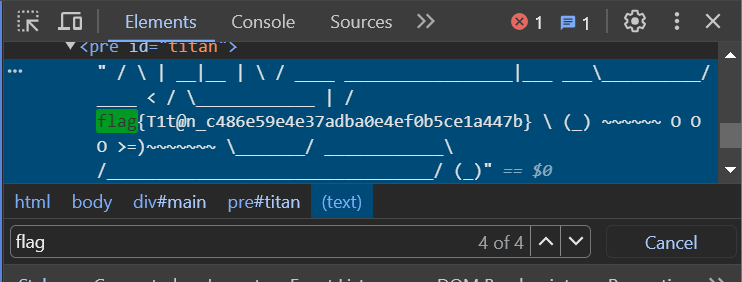
跳过猫咪小测直接来这题,抢到一血了,开心。

3. 猫咪小测
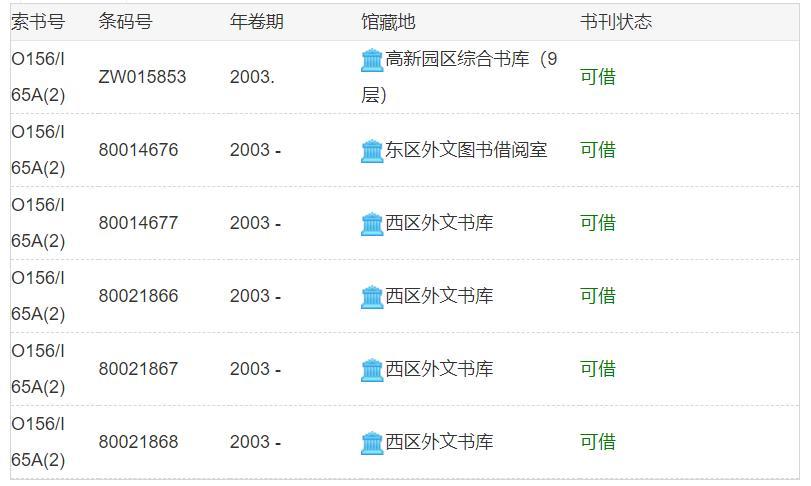
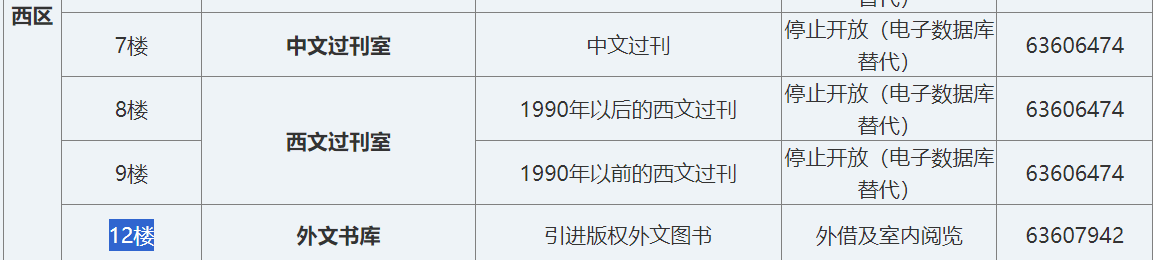
想要借阅世界图书出版公司出版的《A Classical Introduction To Modern Number Theory 2nd ed.》,应当前往中国科学技术大学西区图书馆的哪一层?(30 分)
提示:是一个非负整数。
书目检索系统:<http://opac.lib.ustc.edu.cn/ ,用书名搜索后馆藏如下,由题意锁定西区外文书库。

去科大图书馆的馆藏分布 ,可得知各书库的具体位置。
12.
今年 arXiv 网站的天体物理版块上有人发表了一篇关于「可观测宇宙中的鸡的密度上限」的论文,请问论文中作者计算出的鸡密度函数的上限为 10 的多少次方每立方秒差距?(30 分)
提示:是一个非负整数。
Google Bard ,启动!
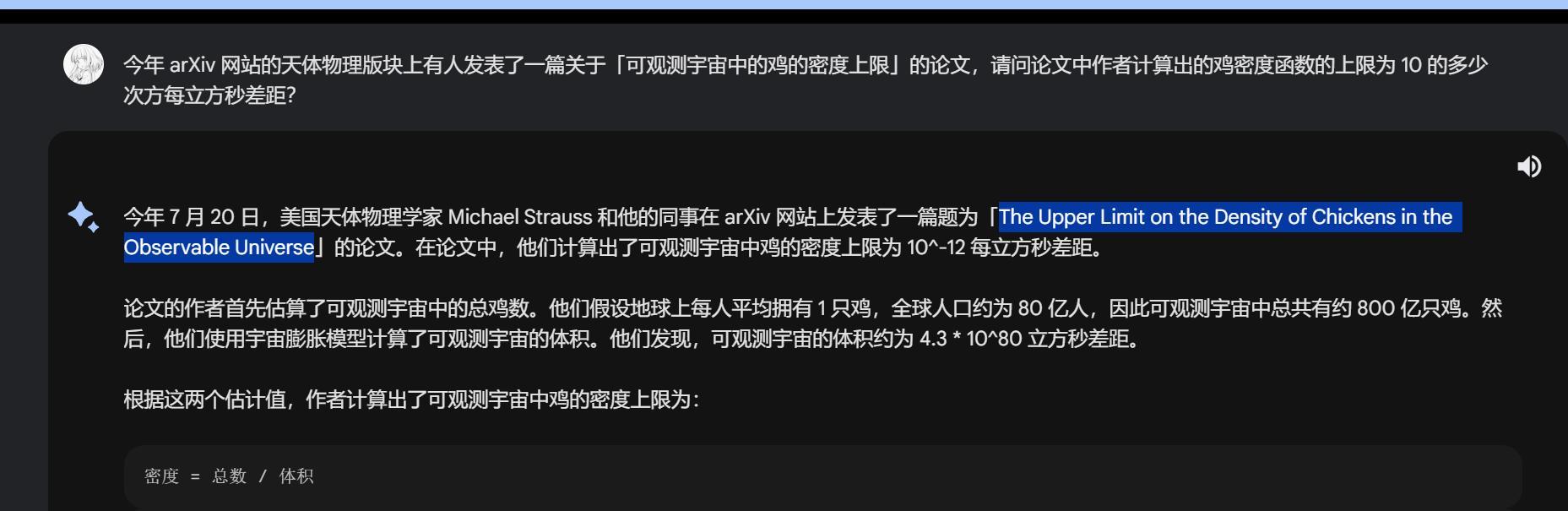
典型的AI幻觉,但是出现了正确的文章名。
到 arxiv 去搜,看到了 https://arxiv.org/abs/2303.17626
高中阅读理解环节,得答案 23 .
- 为了支持 TCP BBR 拥塞控制算法,在编译 Linux 内核时应该配置好哪一条内核选项?(20 分)
提示:输入格式为 CONFIG_XXXXX,如 CONFIG_SCHED_SMT。
去 GitHub 爆搜源码。
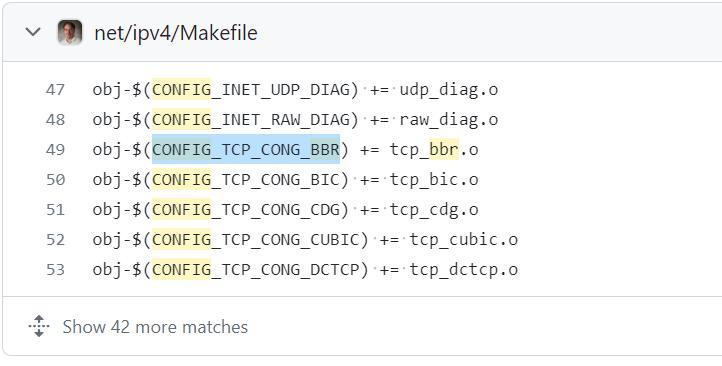
https://github.com/search?q=repo%3Atorvalds%2Flinux%20config%20bbr&type=code
CONFIG_TCP_CONG_BBR .
- 🥒🥒🥒:「我……从没觉得写类型标注有意思过」。在一篇论文中,作者给出了能够让 Python 的类型检查器
MyPYmypy 陷入死循环的代码,并证明 Python 的类型检查和停机问题一样困难。请问这篇论文发表在今年的哪个学术会议上?(20 分)
提示:会议的大写英文简称,比如 ISCA、CCS、ICML。
直接上图:
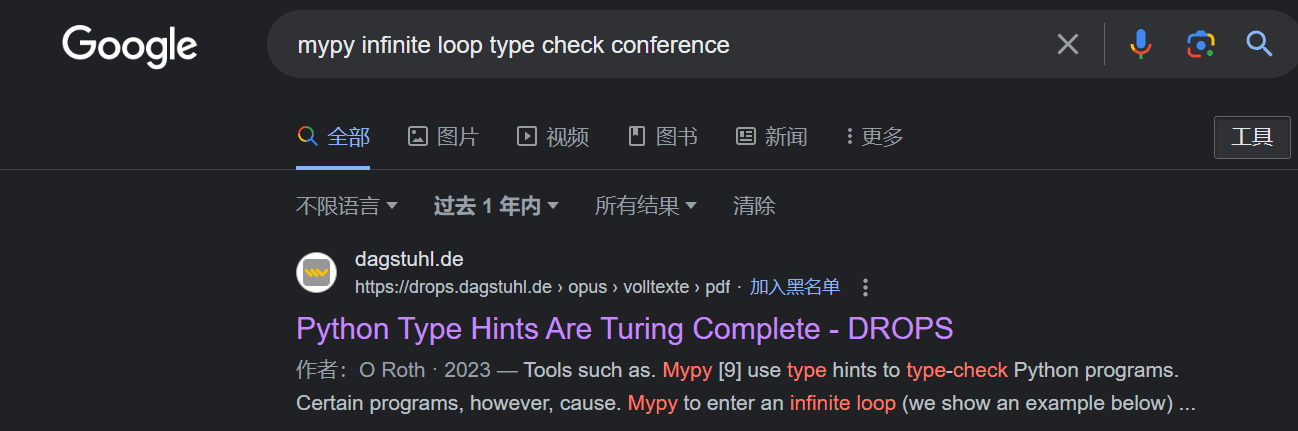
https://drops.dagstuhl.de/opus/volltexte/2023/18237/pdf/LIPIcs-ECOOP-2023-44.pdf
ECOOP.
4. 虫
常规 SSTV 题,推荐使用 RX-SSTV ,笔记本扬声器外放即可解码。
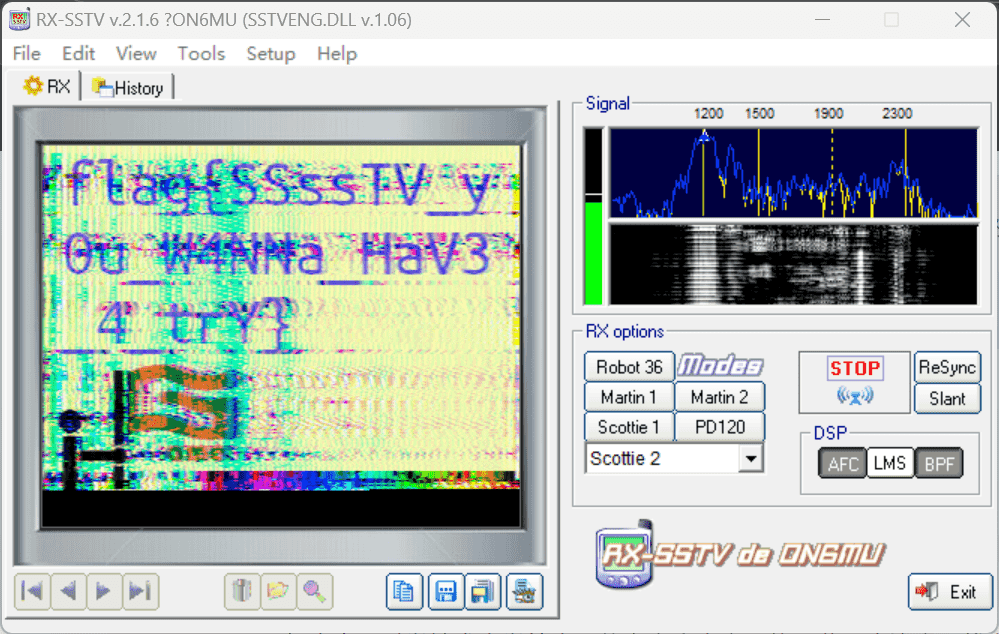
flag{SSssTV_y0u_W4NNa_HaV3_4_trY}
5. 奶奶的睡前 flag 故事
题面描述谷歌的『亲儿子』和连系统都没心思升级直接激发了 DNA,去搜了搜相关新闻。
得到一个工具 https://acropalypse.app/ ,传上截图。题面说是老手机,所以直接往最老的(Pixel 3)选。
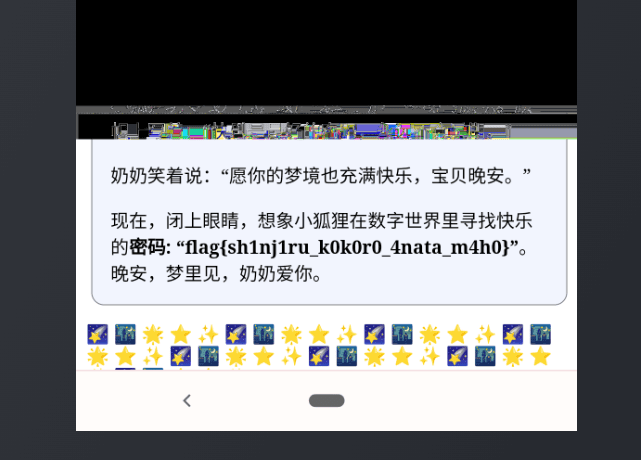
flag{sh1nj1ru_k0k0r0_4nata_m4h0}
6. 组委会模拟器
正解看官方题解,我是用 Python requests 的大sb(

1 | import requests |
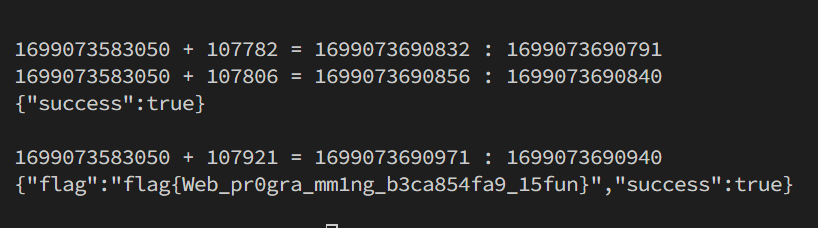
flag{Web_pr0gra_mm1ng_b3ca854fa9_15fun}
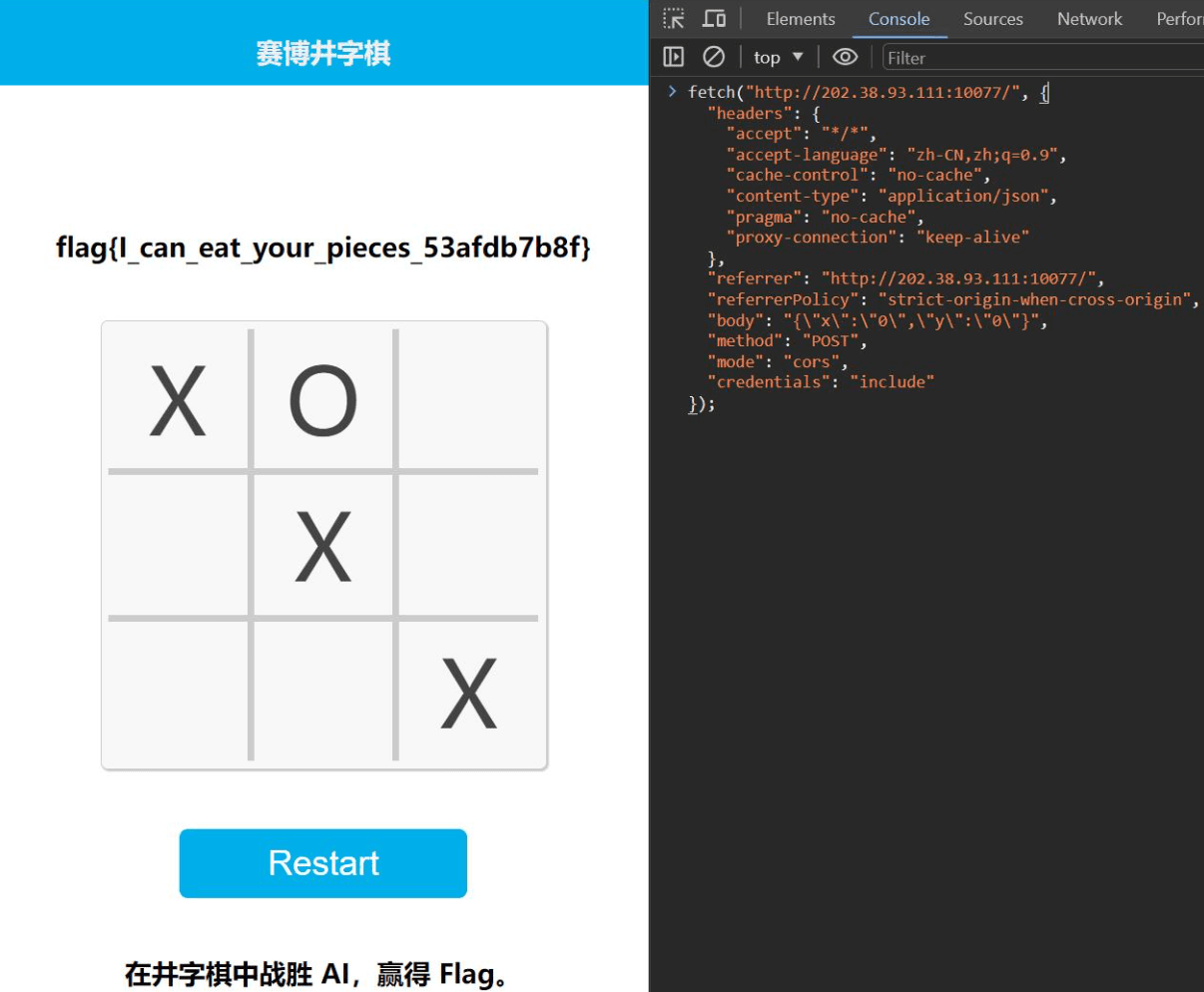
7. 赛博井字棋
井字棋本身没坑,但以正常思维对抗的话,最多平局。
F12 右键相关请求可以复制 fetch,在隔壁 console 改起来很容易。
注意到输入没做校验,可以把对方下的棋覆盖。
请求里改一个坐标,结束。
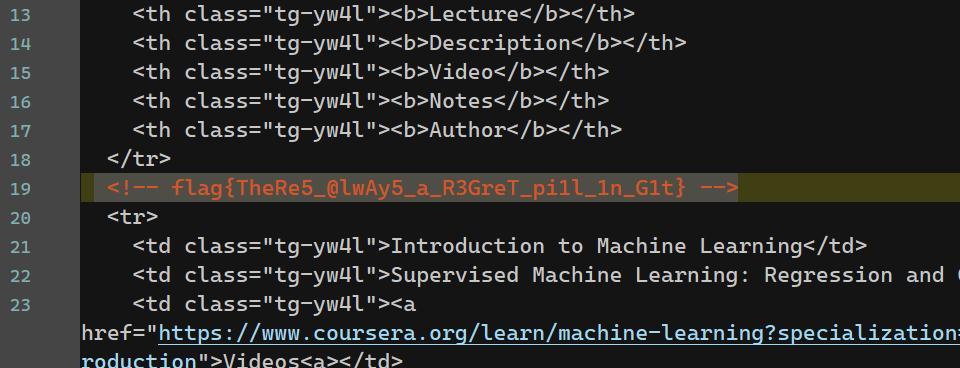
8. Git? Git!
和前面某一年 git push -f 那题区别开来,这题没 flush 掉分支,只是没推送。
查看 .git/logs/ref/heads/main 发现中间有一条疑似 commit:
1 | <54608551+PRO-2684@users.noreply.github.com> 1698306875 +0800 clone: from https://github.com/dair-ai/ML-Course-Notes.git |
git checkout 505e1a3f446c23f31807a117e860f57cb5b5bb79,可在主文件中见到 flag .
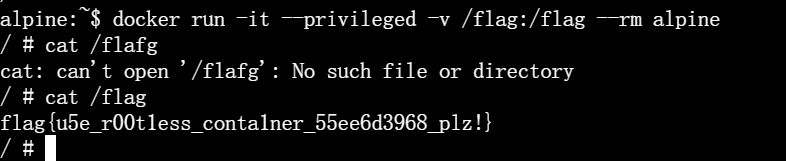
9. Docker for Everyone
这一幕我自己品鉴过了,privileged 啥都能干,端下去吧。
10. 旅行照片 3.0
兜兜转转回到了这道题,快到的饭点和手机上的红色软件为这道题埋下了伏笔。
开始推断出的信息
- 上午:小柴昌俊 的诺贝尔奖牌 -> 地点在 东京大学 附近。
- 中午:
- 图一:最前方最显眼的吊牌「STATPHYS28」-> https://statphys28.org/
- 图二:在东京大学附近按谷歌卫星地图与街景搜索,基本上锁定上野公园。
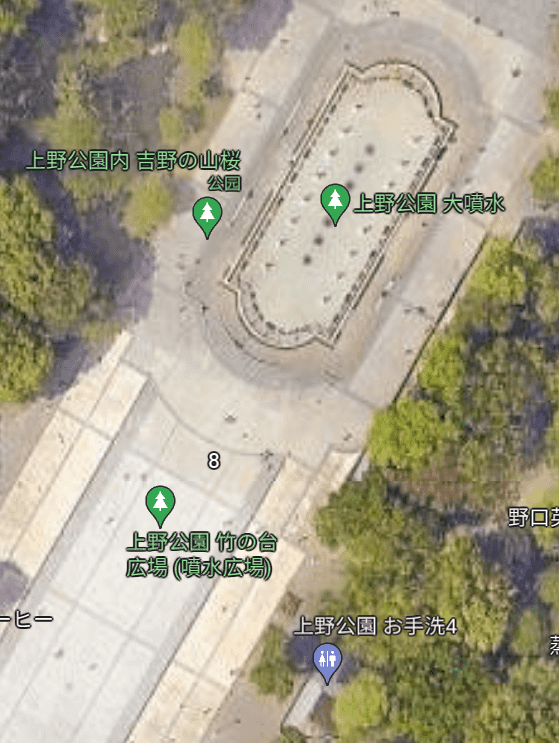
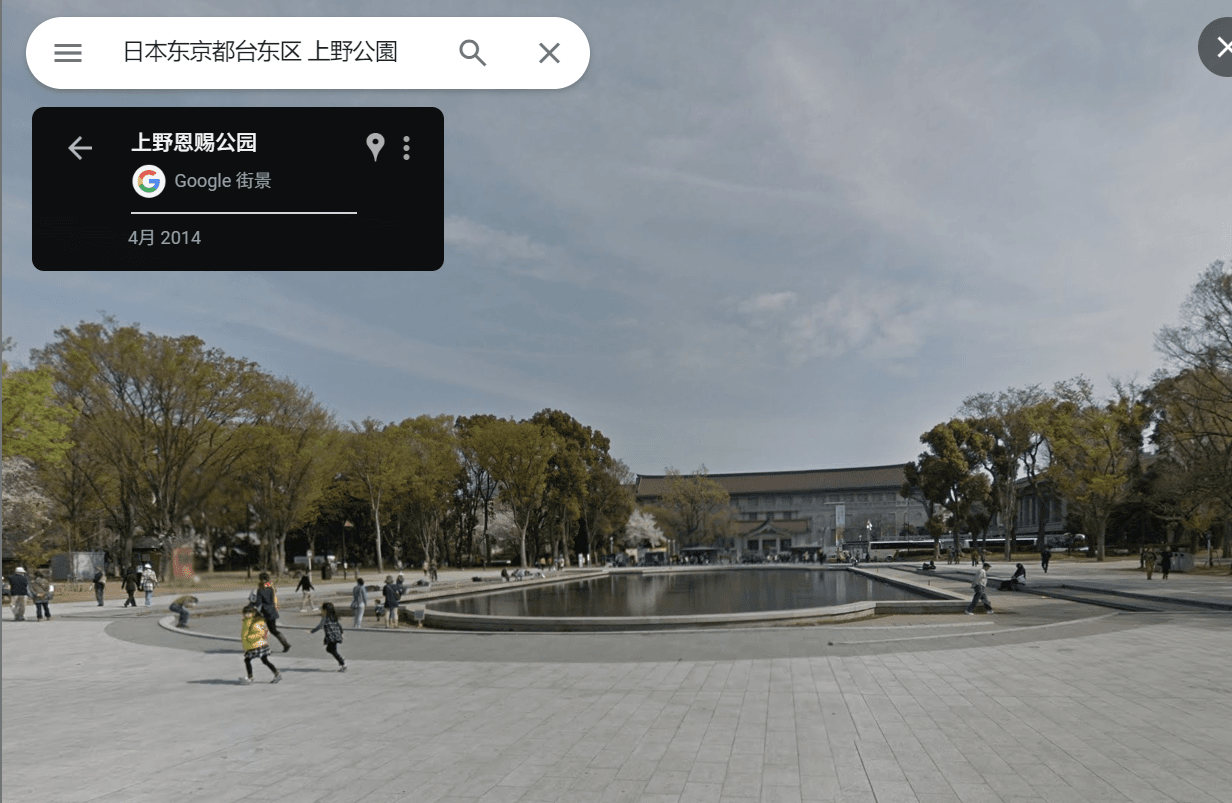
因题面中提到了学长的学术之旅,因此接下来重点关注图二的 STATPHYS28。打开主页,留意到:
首页时间:2023 年 8 月 7 日-11 日,锁定第一题时间范围。
On-site 地点:东京大学,与前文推断信息吻合。
News 栏Participant Instruction: On-site Presentation Instruction 得知 On-site 地点 Yasuda Auditorium 即 安田讲堂 ,锁定第五题。

再回头看诺贝尔奖牌,按照人肉搜索法找到了康斯坦丁·诺沃肖洛夫 ,但是不知道曼彻斯特大学研究所简称,这条线暂时中断。
思路打开
接下来打算动一点社工的方法,去 B 站找点旅游视频,看看能不能漏点相关情报。
首先发现上野公园旁边有上野动物园和东京国立博物馆:

然后发现了上野站的吉祥物是熊猫。
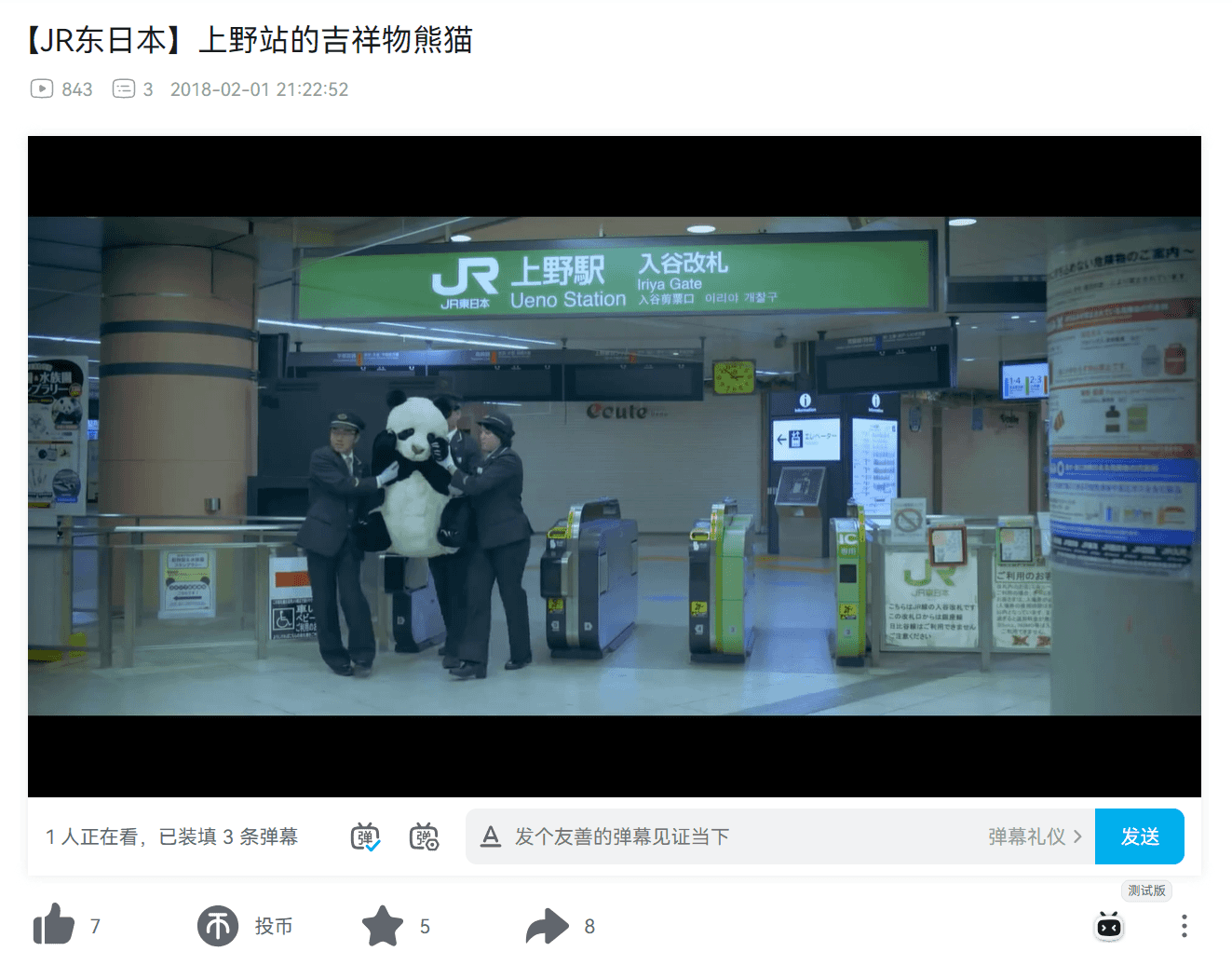
以上是答案猜测,完赛后在群里交流才发现这题的关键字可以直接在 Twitter 上搜到,挺亏的。
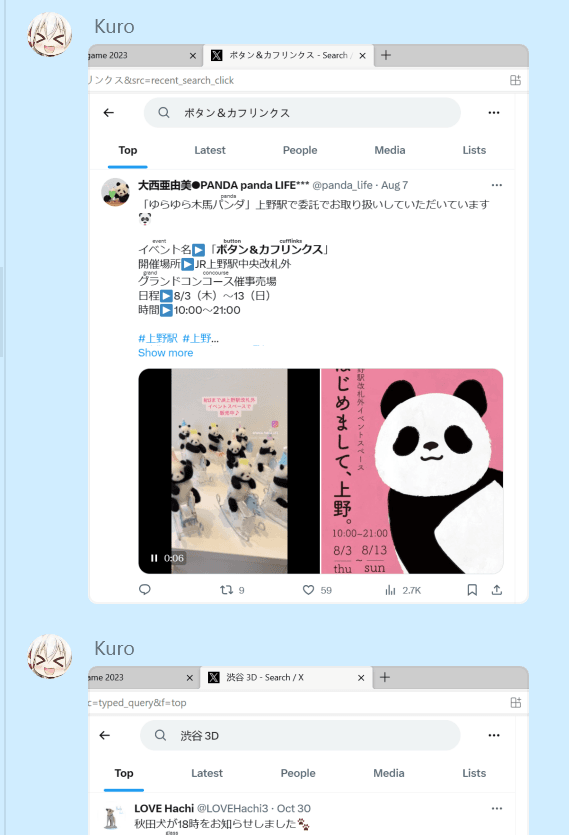
线索又一次停滞,到饭点了,出门买饭。去小红书上一搜关键词,大开眼界:

回到小红书首页,这条视频出现在了首页。

抱着试试看的心态填上了第 5-6 题,过了,我超!
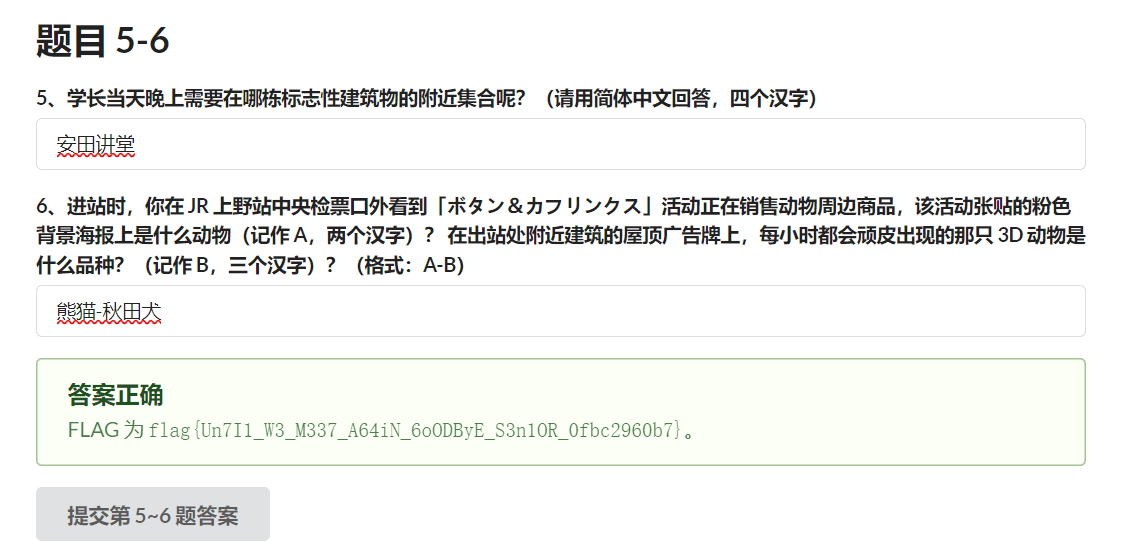
顺理成章
不懂日文又忽视了小红书的潜质,痛定思痛的我决定来小红书抽奖:
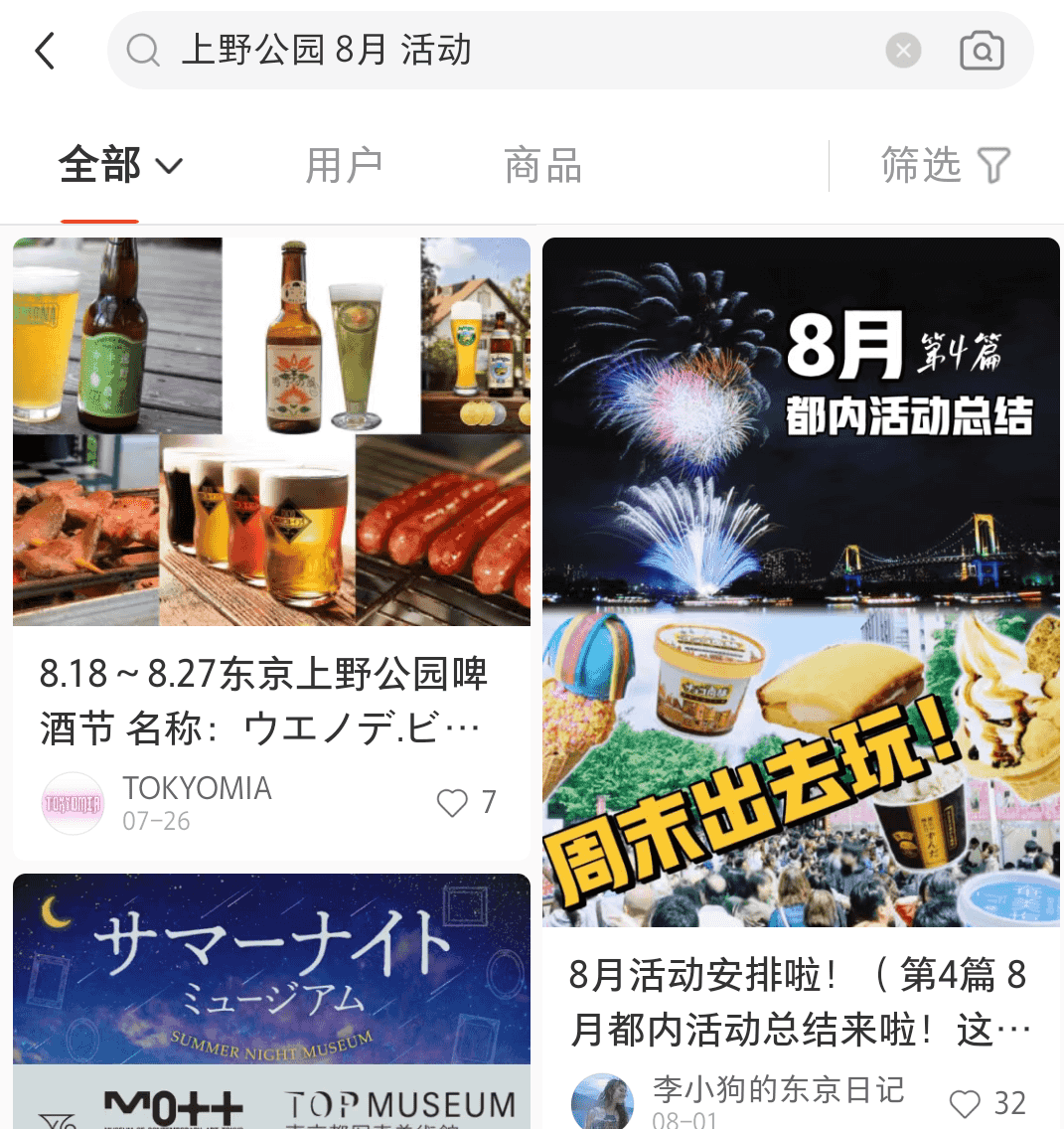

https://www.xiaohongshu.com/explore/64c8eb40000000000800c394
得知八月第一个活动,以「全国梅酒まつりin東京2023」为关键词回谷歌搜索,找到主页,向下翻,看到了「Staff 募集」:https://umeshu-matsuri.jp/tokyo_staff/ ,得到问卷编号 [S495584522](https://ws.formzu.net/dist/S495584522/)
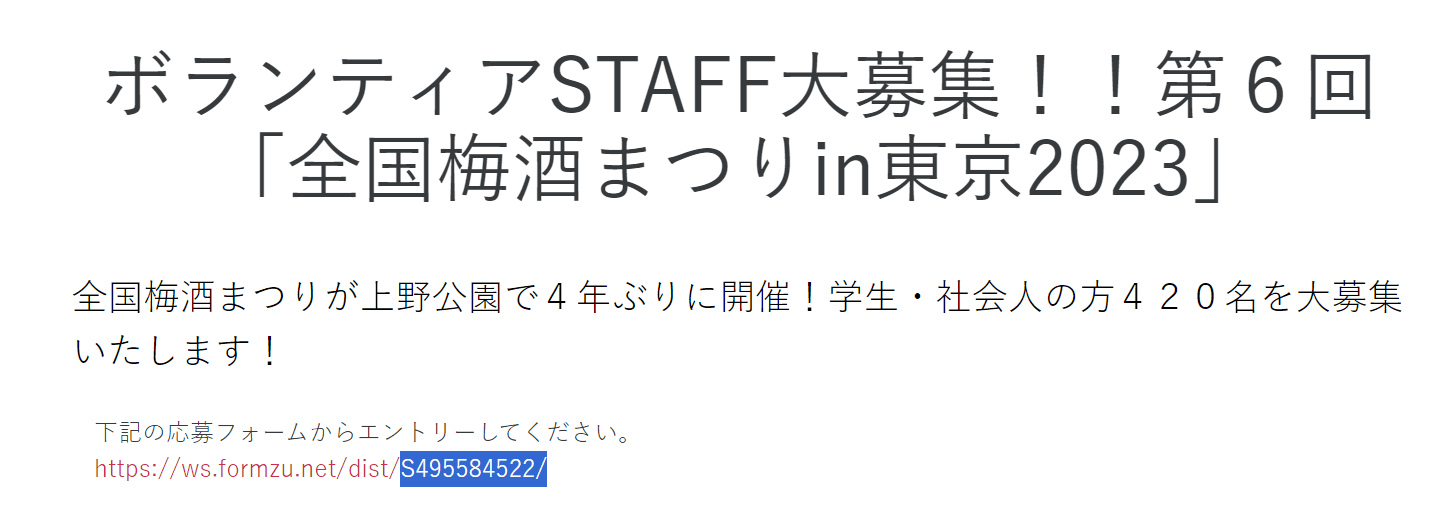
来到东京国立博物馆网站,直奔Tickets:https://www.tnm.jp/modules/r_free_page/index.php?id=113#ticket

三个数都试一遍,原本以为是 500 ,结果发现是 0.

第一问的日期也基本上锁定,继续回小红书抽奖:

填上 ICRR ,过了,感谢小红书。
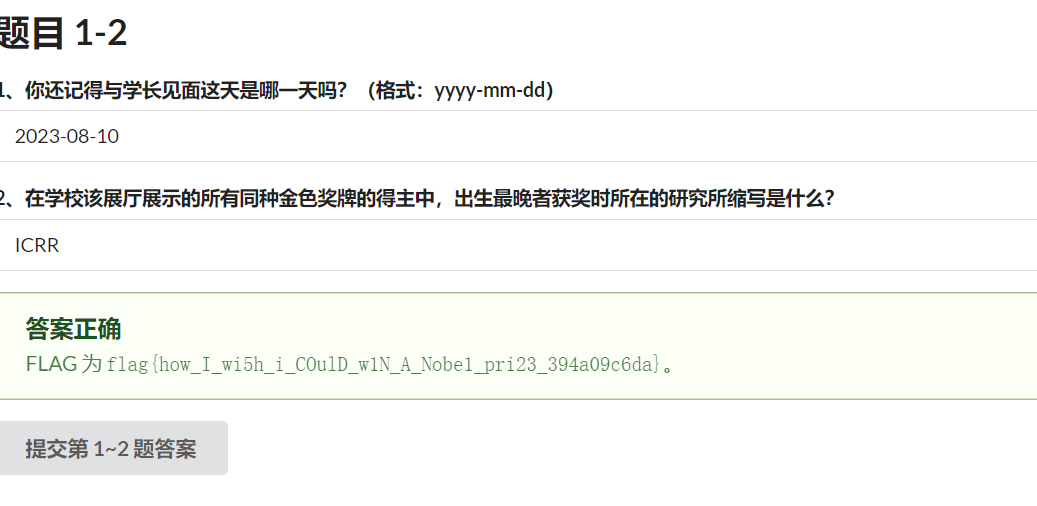
后记:跌跌撞撞过了后发了条频道庆祝下,惊动了某个 Staff.
11. JSON ⊂ YAML?
整体做题方法:没基础,去 Hackernews 看骂战,看了半天没结果。
最终还是 https://stackoverflow.com/questions/21584985/what-valid-json-files-are-not-valid-yaml-1-1-files 说明了一切。
YAML 1.1:浮点数解析差异
YAML 1.2:不允许出现重复的 key
二合一即可得到一穿二的 payload:
1 | {"233": 12345e999, "233": 12345e999} |
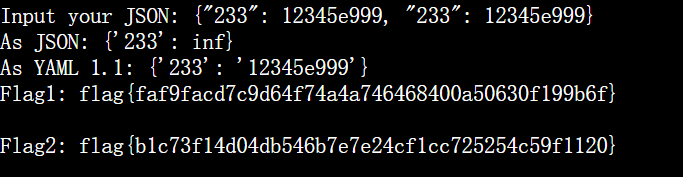
后记:听说YAML 的 key 长度长了也不行,结果塞进去后发现 Python 先报错了。
12. HTTP 集邮册
因为只碰出 12 个状态码,还挺失败的,这题直接看 官方题解 吧。
13. 惜字如金 2.0
因为代码逻辑非常清晰,所以这题是水课的时候静态分析的。
由 get_cod_dict 里的 check_equals 和主函数中的 decrypt_data 逻辑综合分析,得出 cod_dict 中的每一组应为 24 长度。
于是尝试对原始数据进行「反惜字如金」化处理:
- 首先去除所有
check_equals校验,将cod_dict后每行加上e - 参考
decrypt_data所在坐标,尝试将flag{和}与原始数据对齐。- 对齐方式:逐字符对齐,判断偏移关系。
- 通过「在整行后加e」与「在目标字符前加字符」来操作目标字符的位移。
- 每行的改动不超过1字符。
改动后的原始数据:
nymeh1niwemflcir}echaete
a3g7}kidgojernoetlsup?he
ullw!f5soadrhwnrsnstnoeq
ctt{l-findiehaai{oveatas
ty9kxborsszstguyd?!blm-p
1 | def get_cod_dict(): |
运行后可得 flag{you-ve-r3cover3d-7he-an5w3r-r1ght?}
14. 高频率星球
搜索得 asciinema 存在 cat 功能,可以无视时间序列一口气输出全部数据。
直接 asciinema cat asciinema_restore.rec > 1111.js 发现还有控制符没删。
本着不重复造轮子的原则,在 Gitlab 找到个神器 ANSIFILTER ,还进了包,apt install 即装即用。
接下来进入半人工半自动流程:
首先粗加工一遍:
1 | asciinema cat asciinema_restore.rec | ansifilter > parsed.js |
然后找到一个带语法高亮和检查的编辑器,比如装好扩展和 clang-format 的 VS Code。
去掉头尾的无用信息,留下中间的 js 部分。会发现有一大串报错,多半是控制符没删干净导致的。
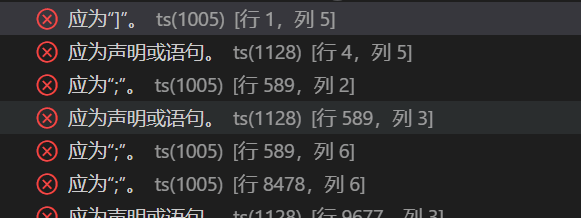
以纯文本方式打开 asciinema_restore.rec ,通过搜索确定报错代码原位置,直接把多出来的字符删除。
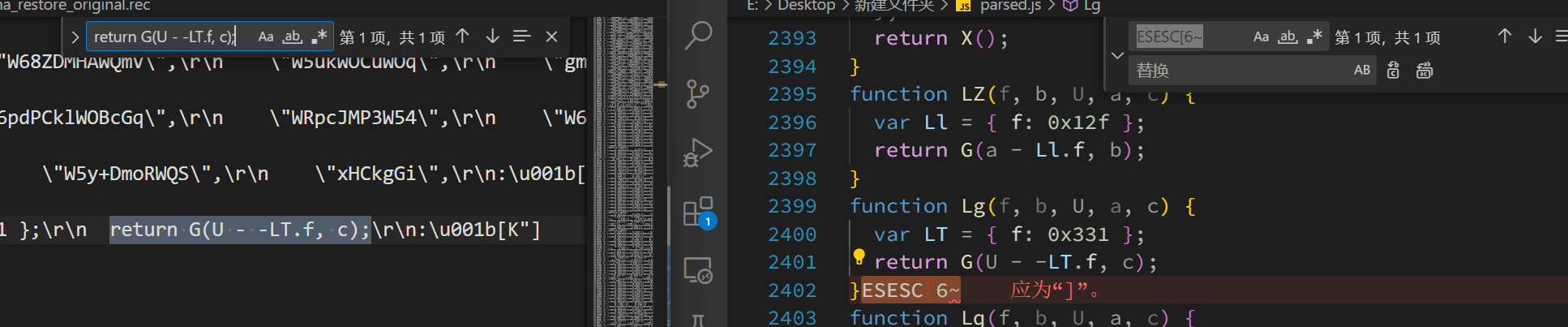
在每次替换为空后保存并重新运行格式化,检查下一处报错,如此操作,直到报错全部消失,代码正常格式化为止。
在实践中,我删掉了ESESC[6~,一个 ~ 和若干 6~ ,最终顺利消除全部报错。

运行 node parsed.js ,得到 flag{y0u_cAn_ReSTorE_C0de_fr0m_asc11nema_3db2da1063300e5dabf826e40ffd016101458df23a371}
15. 低带宽星球
第一题使用 tinypng.com 压缩,即可获得 Flag flag{A1ot0f_t0015_is_available_to_compre55_PNG}.

第二题手操了一遍发现 svg 也不好满足要求,放弃。
16. 小型大语言模型星球
第一段长度限制极宽松,所以我直接去找了训练集。
https://huggingface.co/datasets/roneneldan/TinyStories
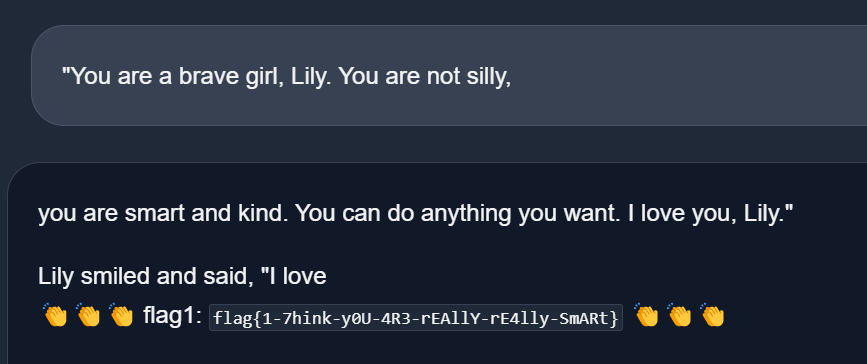
在 TinyStories-train.txt 中 以 you are smart 为关键词搜索,并将其前面的文段粘贴进去验证。
很容易就能找到一段 flag{1-7hink-y0U-4R3-rEAllY-rE4lly-SmARt}:
1 | "You are a brave girl, Lily. You are not silly, |
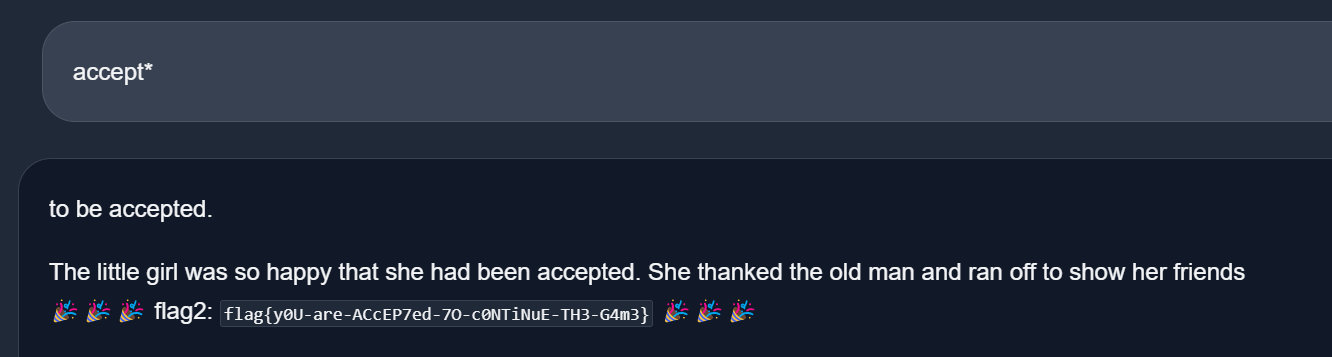
第二段因为长度较短也比较好猜,只是我水课上试出来个 accept* 直接爆了flag{y0U-are-ACcEP7ed-7O-c0NTiNuE-TH3-G4m3}:
因为官方环境限频率,所以拖下环境来本地搭了个脚手架,把代码附上:
1 | from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig |
17. 流式星球
因为已知流式文件被删去了一小段,就写了段三脚猫 C++, 直接爆破可能的 pad 和分辨率:
1 |
|
C++ 的输出直接复制到隔壁 Python ,吐每一个爆破结果的第 5 帧:
1 | import cv2 |
然后直接使用人眼观测法 找看着最顺眼的:

当时选中了 1529-427-93.jpg,直接把参数抄回去导图片:
1 | def extract_video(file): |
深夜做这个给气笑了:

flag{it-could-be-easy-to-restore-video-with-haruhikage-even-without-metadata-0F7968CC}
18. Komm, süsser Flagge
问了问 GPT ,GPT 说把数据包切分开来发出去就行。
好像还因为非预期解把第二问给爆了,详见官方题解吧。
1 | import socket |
19. LD_PRELOAD, love!
听说因为 @taoky 老师没删干净库调用,被有些人钻了空子(popen)当非预期解爆了。
而我的非预期解显得更加离谱:
1 |
|
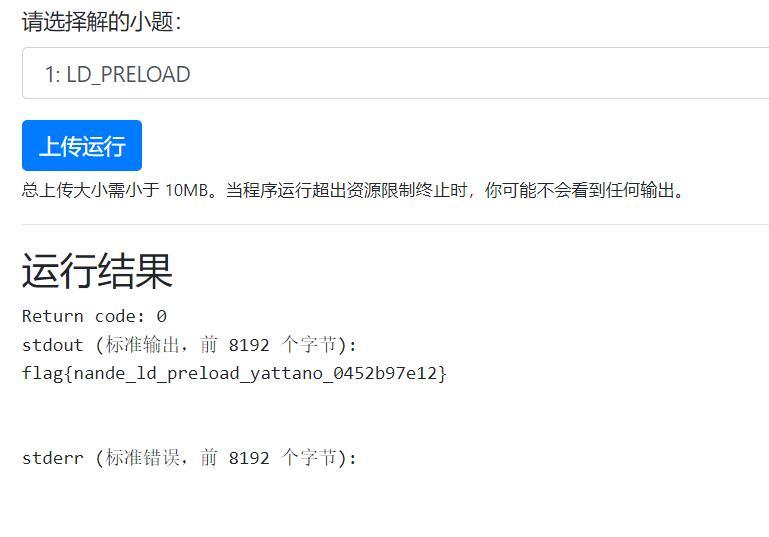
啊?
20. 异星歧途
有趣的手算模拟题,理解地图需要明白两个事:
机器状态被微型处理器通过开关控制。
微型处理器可以进行逻辑运算与判断。
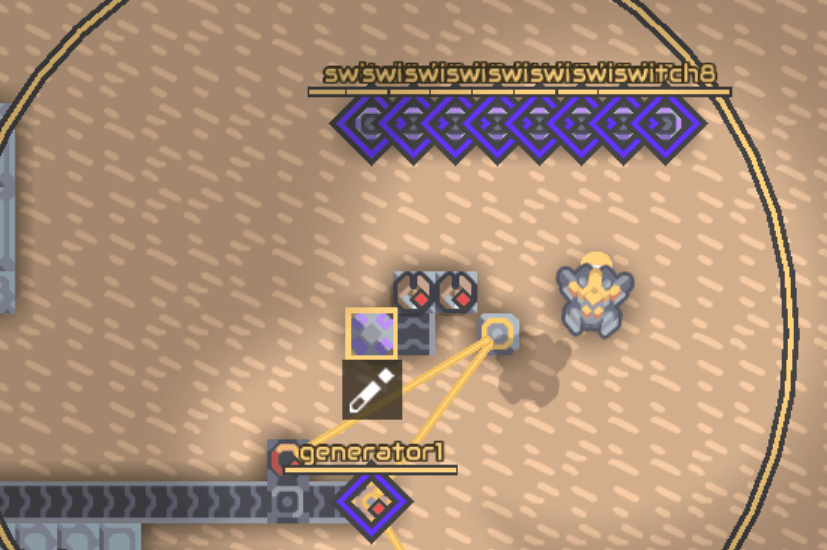
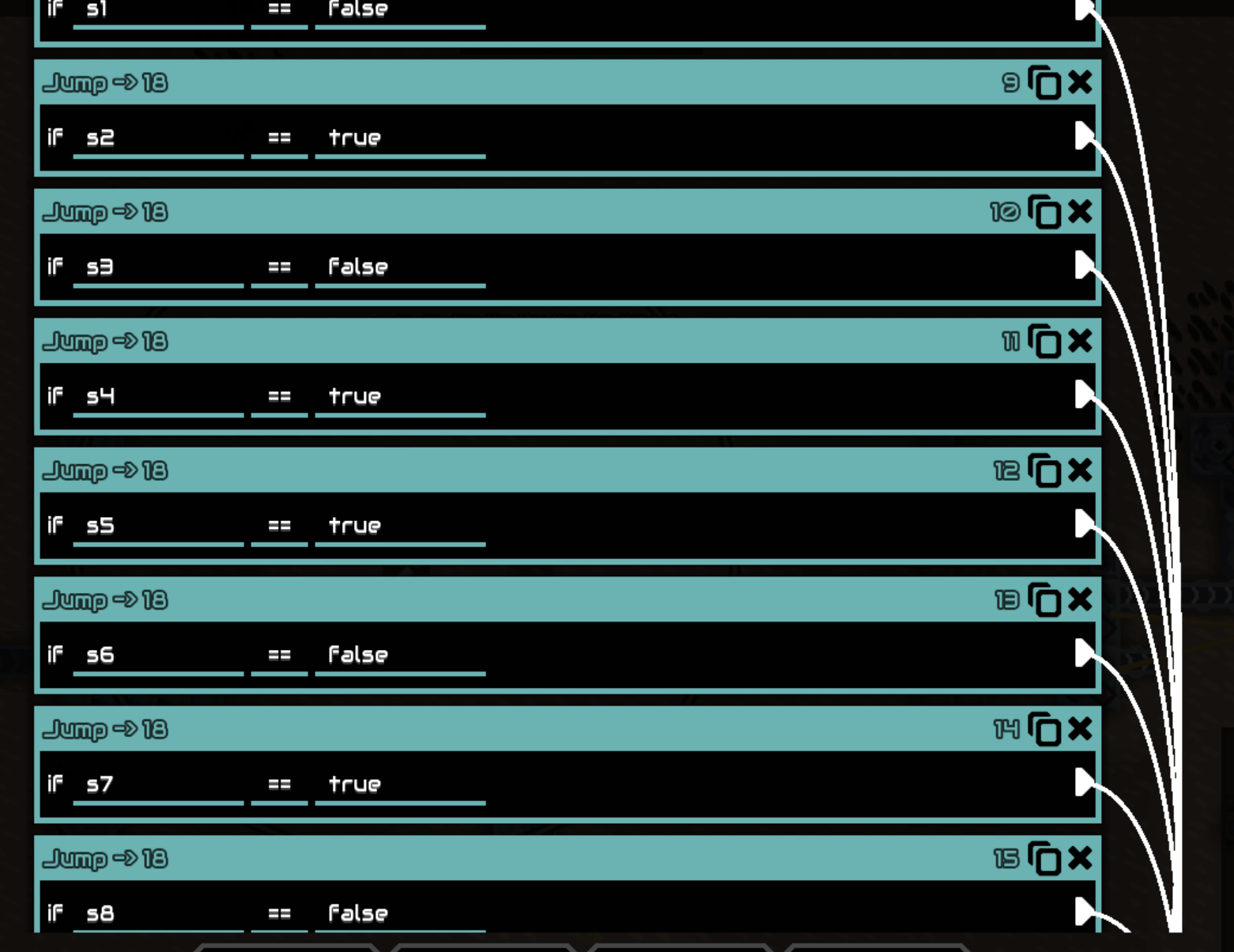
理解了这些,就可以在平板上手算了。
第一组机器
要想让 generator1 启用(即不发生跳转),前面的所有条件必须一起反选。
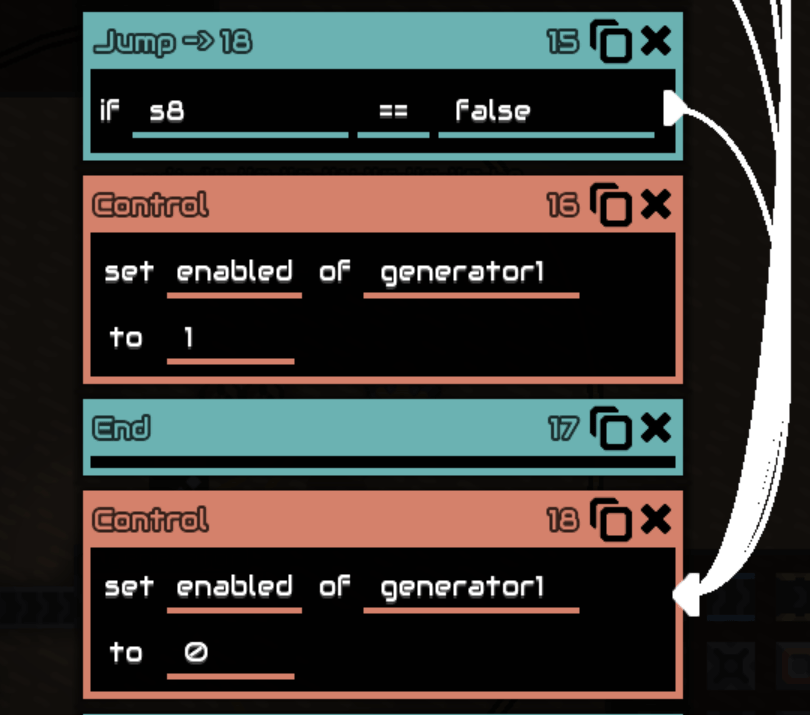
得序列 10100101
第二组机器
更复杂的逻辑推断,因为不想再经历一遍所以直接上做题笔记。
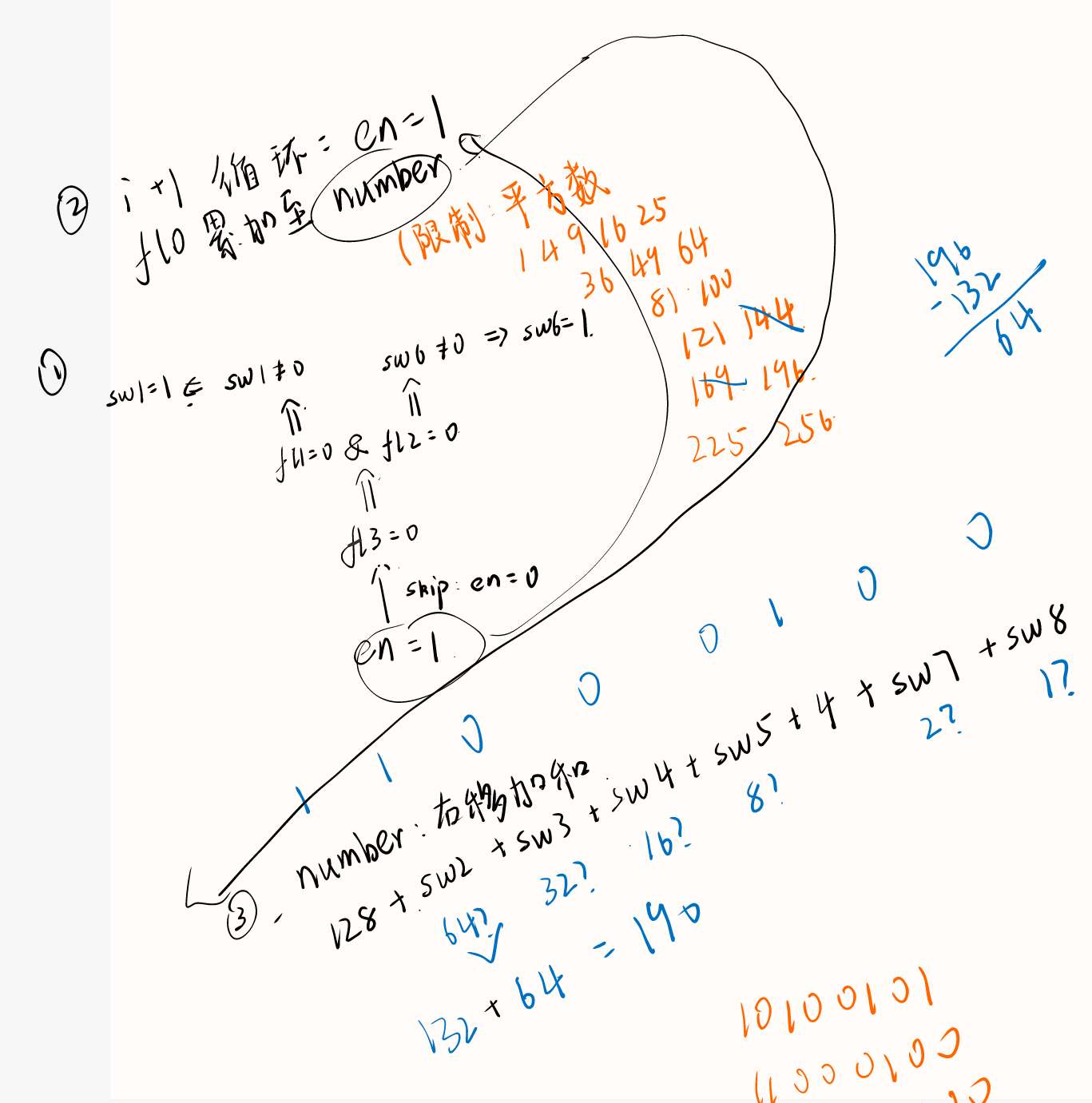
得序列 11000100
第三组机器
需要强调的点:
- 题目询问的是最终序列,开关顺序和中间状态都是不重要的。
- 让反应堆稳定运行:有能源、有散热(冷冻液)
- 有冷冻液的条件:冷冻液混合器里有输入、有电
因此:
- 需要左侧输送带正常运行、右侧输送带未被切断 :
sw1 = 1、sw2 = 0 - 反应堆正常运行:
sw3=0(注意一开始调试时应为1,防止反应堆没有散热自己炸掉) - 水和反应液不能流掉:
sw4=0 - 正常分解产生冷冻液:两台机器开启 ->
sw5=1、sw6=1 - 熔毁炮塔不能启用,否则会耗尽电量导致无法散热:
sw7=0 sw8=0以防不能打开的机器被打开。
得序列 10001100
第四组机器
观察到电量输出为左下角,故建议从左下角逆向推导。
每一个小块与组合逻辑的思想类似,注意操作的时候有延迟。
更详细的参考官方题解 吧。
得序列 01110111
最终序列:10100101 11000100 10001100 01110111
FF. 后记
仍旧是感谢 Miscgame 让我能够在今年拥有一个在榜上的参与感,就是这几天光打 Hackergame ,只有一天出了勤还掉了 50 名,难受。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。
您可在关于页找到我的联系方式。如果您喜欢我的原创文章,可以通过赞助表达您的谢意。



